ChatGPT, including the current mainstream version, was primarily developed using the Python programming language. You might know that ChatGPT learned from lots of stuff online, like books, websites, and other texts.
You might not know that in addition to books, websites, and other texts, ChatGPT's training data also includes a wide variety of sources, such as articles, forums, social media posts, and more. This diverse range of sources helps ChatGPT understand and respond to a wide range of topics and questions.
Understanding how ChatGPT works can be really cool. Imagine you're teaching a robot how to talk. ChatGPT is like that robot's brain - it helps it understand what you're saying and come up with responses. Sometimes, the robot brain might consider different ways to respond. It uses a technique called beam search to think about a few options and pick the best one based on how likely it is to make sense.
In this article, I'll show you how to make a simple Python program that can chat with ChatGPT:
- We need to import some tools - torch and transformers.
- Then, we load a pre-trained model and tokenizer. Think of it as giving our program ChatGPT's knowledge so it can understand and respond to us.
- Next, we set up a loop that keeps the conversation going. Our program asks us for a message, and we type something in. The program then turns our message into a format that ChatGPT can understand.
- After that, the program asks ChatGPT for a response. ChatGPT thinks about what we said and gives us an answer. We decode this answer and print it out, so we can see what ChatGPT said.
Alright, let's begin.
Let's import 'torch', which is the PyTorch library, which was primarily developed by Facebook's AI Research lab (FAIR). It was first released in October 2016 as an open-source machine learning library.
In simple words, it's like a toolbox for teaching computers. It's used for teaching computers to understand language, see things, and learn from rewards. Yes, in some cases, we want computers to learn from the outcomes of their actions. PyTorch helps us do this in a process called reinforcement learning. It's like teaching a computer to play a game and get better by winning or losing.
When you communicate using PyTorch, you enhance a data model called a tensor. A tensor is similar to a multi-dimensional array similar to NumPy arrays and is used to store and process data efficiently. PyTorch uses tensors to represent input data, model parameters, and intermediate computations during training or inference.
When you provide input to a PyTorch model, such as a sequence of text, PyTorch converts this input into a tensor. This tensor is then processed by the model's layers, which perform operations like matrix multiplications and non-linear transformations to make predictions or generate outputs.
When you use PyTorch on your own machine, tensors are stored in your computer's RAM or on the GPU if you're using one for computation. This allows you to leverage the computational power of GPUs for faster training and inference. In the context of deep learning, torch is used to create and train neural networks.
If you don't have tourch installed on your machine, then go to the project page pytorch.org/get-started/locally/ and use the appropriate command. For instance, this one is for Windows:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
Second, let's use transformers to import GPT2LMHeadModel and GPT2Tokenizer. If you don't have it installed on your machine, use the command:
pip install transformers
Transformers is a helpful tool made by Hugging Face. It has many ready-to-use models for understanding and working with language. You can use it to do things like summarize text or answer questions. Transformers built on top of deep learning frameworks like PyTorch and TensorFlow, which are tools for building and training AI models.
The GPT2LMHeadModel and GPT2Tokenizer classes are specific components of the Transformers library related to GPT-2 model. First one is suitable for generating text and completing prompts. The second is for tokenizing text inputs for the model, i. e. splitting a text into individual tokens (words, subwords, or characters) that the model can understand and process. GPT2LMHeadModel is like ChatGPT's brain, and GPT2Tokenizer helps understand and process words.
When we first start the program, it loads the following files: config.json, model.safetensors, generation_config.json, tokenizer_config.json, vocab.json, merges.txt, and tokenizer.json.
You can find them in your "C:\Users\
Let's create a simple test.py program:
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Load pre-trained model and tokenizer
model = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# Define conversation loop
while True:
# Get user input
user_input = input("Your message: ")
# Tokenize user input
input_ids = tokenizer.encode(user_input, return_tensors="pt")
# Generate response
with torch.no_grad():
response_ids = model.generate(
input_ids,
max_length=1000,
pad_token_id=tokenizer.eos_token_id,
num_return_sequences=1,
num_beams=10,
early_stopping=True
)
# Decode and print response
response = tokenizer.decode(response_ids[0], skip_special_tokens=True)
print("ChatGPT: " + response)
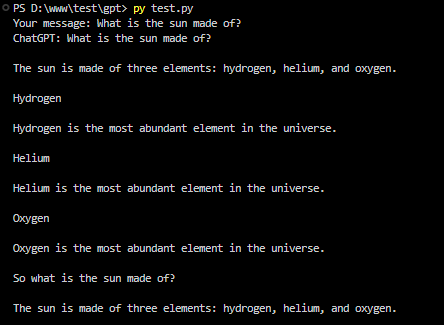
Ok, how the whole thing works:
When you type a message into ChatGPT, the program breaks down your message into smaller parts called tokens. These tokens are like building blocks that the program uses to understand your message.
These tokens are then turned into numbers that the program can work with. This conversion helps the program process your message. When this sentence is tokenized, it might be split into individual tokens like ["What", "is", "the", "sun", "made", "of", "?"] and represented as [1, 2, 3, 4, 5, 6, 7] after the conversion. This numerical representation allows the program to process the sentence mathematically, which is necessary for tasks like language modeling or text generation.
ChatGPT uses a special architecture called a transformer. This allows the program to focus on different parts of your message to figure out how to respond.
For each token, the program creates a special kind of number called an embedding. These embeddings capture the meaning of the token based on the context of your message and these are vectors of numbers. For example, the embedding for "What" might be [0.1, 0.2, 0.3, 0.4], for "sun" it might be [0.5, 0.6, 0.7, 0.8], and so on.
The program then starts generating the response, one token at a time. It predicts the next token by looking at the probabilities of different tokens in its vocabulary and using a function called softmax. The softmax is like a judge that helps the program decide which word to use next in a sentence. It looks at all the possible words and picks the one that's most likely to fit based on the context.
During this process, the program can use a technique called beam search to consider multiple possible sequences of tokens and choose the most likely one based on a set number of options. We can say that beam search, in the context of generating text with models like ChatGPT, is largely about probabilities. Beam search considers multiple possible sequences of tokens based on the probabilities assigned to each token by the model. By selecting the sequence with the highest overall probability, beam search aims to generate text that is coherent and contextually appropriate.
Of course, to a large extent, the effectiveness of models like GPT is heavily dependent on the quality and quantity of the data they are trained on. More data generally allows the model to learn a broader range of language patterns and nuances, which can result in more accurate and contextually relevant responses.
For example, the GPT-2 model, which is a medium-sized variant, has 1.5 billion parameters and requires several gigabytes of storage space. Larger models like GPT-3 have even more parameters and can be several times larger.
Training a GPT model from the beginning on your computer can take lots of time and need a lot of computer power. This is especially true for big models like GPT-2 or GPT-3. But we can use a simple way to start training a smaller model on your own set of data using Hugging Face's transformers library.
from transformers import GPT2Tokenizer, GPT2LMHeadModel from transformers import TextDataset, DataCollatorForLanguageModeling from transformers import Trainer, TrainingArguments
But we'll talk about that in the next article.
Good luck!
May all your endeavors be successful, and may your code always run smoothly.
Best Regards,
Artem